Spam and Ham Classification System: Filtering Unwanted Messages with Multinomial Naive Bayes
Introduction
The Spam and Ham Filtering project aims to develop a machine learning model that can accurately classify incoming messages as either "spam" or "ham" (non-spam). By utilizing the Multinomial Naive Bayes algorithm and text processing techniques, this project focuses on creating an e�cient and effective system for filtering unwanted and potentially harmful messages.
Data Description
A spam and ham email dataset is a collection of emails that are categorized into two main groups: spam and ham.
Spam Emails: These are unsolicited, unwanted emails that are typically sent in bulk to a large number of recipients. They often contain advertisements, promotional offers, or fraudulent content. Spam emails are usually sent with the intention of deceiving or tricking recipients into taking certain actions, such as purchasing a product, revealing personal information, or clicking on malicious links.
Ham Emails: These are legitimate, non-spam emails that are desired or expected by the recipients. Ham emails can include personal or professional correspondence, newsletters, transactional emails, or any other legitimate communication that users have opted to receive.
Project Steps
Data Preprocessing:
The provided dataset is analyzed, which contains messages labeled as either "spam" or "ham." Descriptive statistics are generated to gain insights into the distribution of spam and ham messages.
Data Transformation: A new column, "spam," is created in the dataset by replacing the "spam" and "ham" labels with numerical values (1 for "spam" and 0 for "ham"). The updated dataset is displayed to verify the changes.
Data Splitting: The dataset is split into training and testing sets, with 75% used for training and 25% for evaluation. The messages are separated into input features (X) and the corresponding spam labels (y).
Feature Extraction: The CountVectorizer is initialized to transform the text data into a matrix of token counts. The CountVectorizer is fit on the training data and transforms both the training and testing data.
Model Training: A Multinomial Naive Bayes classifier is instantiated. The classifier is trained using the training data to learn patterns and relationships between the input features and the spam labels..
Spam and Ham Prediction: New email messages are created and transformed into token count matrices using the fitted CountVectorizer. The trained model predicts the class labels (spam or ham) for the new email messages.
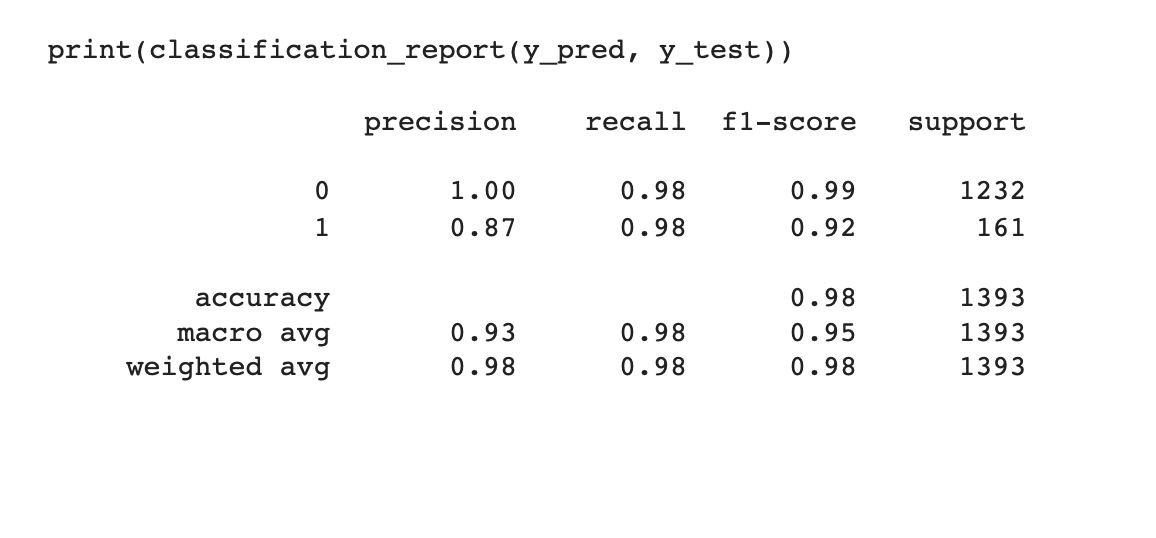
Model Evaluation: The model's performance is evaluated using a classification report. The classification report provides precision, recall, F1-score, and support metrics for both the ham and spam classes.
The Spam and Ham Filtering project leverages the Multinomial Naive Bayes algorithm to accurately classify messages as spam or ham. By preprocessing the data, transforming text into numerical features, and training the model, it becomes possible to predict the spam or ham label for new messages. The evaluation metrics from the classification report help assess the model's effectiveness in distinguishing between spam and ham messages.
This project provides a foundation for developing a robust spam filtering system that can be implemented in various applications to reduce the impact of unwanted and potentially harmful messages on users' digital experiences.
Conclusions
In conclusion, the evaluation of the machine learning model on the spam dataset indicates its strong performance in classifying emails as spam or ham. The model achieved an impressive accuracy of 98%, demonstrating its ability to correctly classify a majority of the emails in the dataset.
The model's high precision and recall scores, as indicated by the macro and weighted average metrics, further emphasize its effectiveness. This suggests that the model achieved a good balance between identifying spam emails accurately and correctly categorizing legitimate ham emails.
Overall, these findings suggest that the machine learning model trained on the spam dataset is a robust solution for email classification. It shows promising performance in accurately identifying and filtering out spam emails, thereby providing users with a more streamlined and reliable email experience.