Classification Report
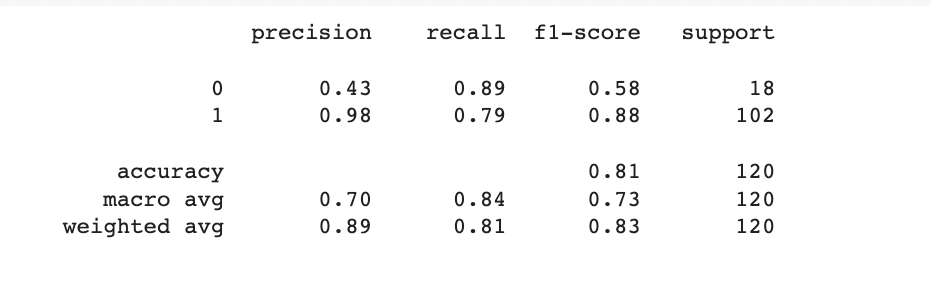
The evaluation metrics provide insights into the performance of the SVM model for loan status prediction. Here is an analysis of the metrics:
- Precision: Precision is a measure of the model's ability to correctly identify positive predictions (loan applications approved) out of the total predicted positive cases. The precision for class 0 (rejected loans) is 0.43, indicating that 43% of the predicted rejected loans were correct. For class 1 (approved loans), the precision is 0.98, indicating a high level of accuracy in identifying approved loans.
- Recall: Recall, also known as sensitivity or true positive rate, measures the model's ability to identify the actual positive cases (loan applications approved) out of the total positive cases. The recall for class 0 is 0.89, indicating that the model successfully identified 89% of the actual rejected loans. The recall for class 1 is 0.79, indicating that the model captured 79% of the actual approved loans.
- F1-score: The F1-score is the harmonic mean of precision and recall, providing a balanced measure of the model's accuracy. The F1-score for class 0 is 0.58, which indicates a moderate balance between precision and recall for rejected loans. For class 1, the F1-score is 0.88, indicating a high level of accuracy and balance between precision and recall for approved loans.
- Support: The support column represents the number of samples in each class (0 and 1). In this case, there are 18 samples for class 0 (rejected loans) and 102 samples for class 1 (approved loans).
- Accuracy: The overall accuracy of the model is 0.81, indicating that the model correctly classified 81% of the loan applications in the testing set.
- Macro Avg: The macro average calculates the average performance of the model across both classes, giving equal weight to each class. The macro average precision, recall, and F1-score are 0.70, 0.84, and 0.73, respectively.
- Weighted Avg: The weighted average calculates the average performance, considering the number of samples in each class. The weighted average precision, recall, and F1-score are 0.89, 0.81, and 0.83, respectively.
Overall, the model shows reasonably good performance in predicting loan status. It achieves high precision, recall, and F1-score for approved loans (class 1), indicating its effectiveness in identifying successful loan applications. However, there is room for improvement in accurately identifying rejected loan applications (class 0), as indicated by the lower precision, recall, and F1-score.